PHP: dalla prigione di MySQL al paradiso degli ORM.
dev /
Chiunque abbia mai sviluppato per il web nella propria carriera di programmatore, avrà prodotto con orgoglio il seguente snippet di codice (con me in testa):
$result = mysql_query("SELECT * FROM news");
while($row = mysql_fetch_array($result)){
// aggiungete fronzoli html a piacere
echo $row['title'];
echo $row['body'];
}
Et voilà, il nostro blogghettino era quasi pronto. Bene, tale approccio apparentemente cheap e remunerante, è quanto di più inefficacie ed immantenibile si possa produrre in un ambiente di sviluppo web attuale.
Chiunque nel settore sia vissuto fuori da un igloo negli ultimi 5 anni, sarà incorso in magiche buzzword quali Web MVC, PHP OOP, ORM, che sono diventati a buon diritto standard di produttività. Circa le primi due vi rimando ad un paio di letture illuminanti, mentre prima di riferirmi alla terza, passo a spiegare il perché del titolo del post: quando dico che lo sviluppatore junior di PHP è schiavo di MySQL, mi riferisco al fatto che il database viene spesso visto come un elemento vivo del ciclo di vita dell'applicazione / sito web.
No, il database (e relativo strato di accesso al medesimo) è solo uno strumento di persistenza, del quale per assurdo si potrebbe fare a meno se il computer dove gira il programma (in questo caso il server dove sta girando Apache) potesse tenere tutte le informazioni in RAM. Siamo poi tutti coscienti del fatto che questo non sia possibile, e che il salvataggio delle entità interessate in una struttura organizzata come un RDBMS (Relational Database Management System) sia inevitabile e vantaggioso; del resto se il db è strutturato in maniera coerente, esso garantisce integrità dei dati e rapido accesso ai medesimi.
Questo vuol dire semplicemente che il layer di persistenza non deve essere solo trasparente a quello business, bensì non deve inficiarne la consistenza minandolo di workaround, frutto ad esempio di nomenclatura sconsiderata delle tablle relative: design for goals, not for technology!
Case Study: MyLittleLibrary
Sviluppiamo in pochi passi il prototipo di un semplice sistema di gestione di una libreria personale: profiliamo allora le entità protagoniste.
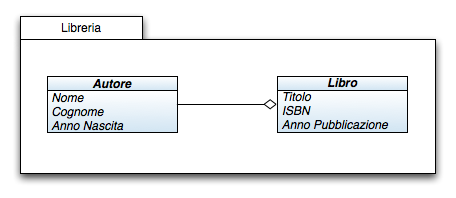
"Ogni libro può avere uno o più autori" - per ora direi che può bastare. Per comodità d'esempio poniamo vero che un numero consistente di autori sia già all'interno del programma, limitando la procedura di inserimento ai soli dati relativi ai libri.
In prehistoricphp fareste:
$insert = mysql_query(
sprintf("INSERT INTO libri VALUES(NULL, %s, %s, %s, %s",
$_POST['titolo'],
$_POST['ISBN'],
$_POST['anno'],
$_POST['id_autore']
)
);
mysql_query($insert) or die "Vado ad imparare PHP 5.3";
Una roba del genere, finché il vostro capo non vi chiederà di inserire un nuovo campo all'interno del libro - e per semplicità mi risparmio la tabella di relazione molti-a-molti. I più svegli avranno quantomeno delegato a PDO la gestione delle query, ma non è sufficiente: io voglio un codice snello e che rifletta il mio percorso mentale per fare un'operazione così elementare, proviamo così:
$libro = new Libro();
$libro -> isbn = $request -> isbn;
$libro -> anno = $request -> anno;
foreach($request -> autori as $autore)
{
$libro -> autori -> add(Autore::find($autore);
}
$libro -> create();
Creo un libro vuoto, vi aggiungo le proprietà (prelevate da un oggetto Request che incapsuli la richiesta http e la pulisca da problemi di encoding / XSS), indifferentemente dal fatto che siano tipi nativi (interi, stringhe) o collezioni di oggetti, e poi la salvo. È il metodo create() ad essere delegato alla persistenza, e non il controller che gestisce la richiesta. Tutto il sostrato che muta la vostra bella e pulità entità in un groviglio di tabelle è compito degli strati inferiori, sostenuti ed aiutati dal Convention over Configuration principle:
- chiamate le tabelle con i nomi delle entità;
- chiamate i campi delle tabelle con i nomi dei campi delle entità;
- delegare possibilmente il tutto in maniera esplicita ad annotazioni inline;
In sintesi, ponete enfasi sulla descrizione del modello, e non sul boilerplate del reperimento e della persistenza dei dati, che deve essere totalmente trasparente. Il consiglio che vi do è quello di sviluppare il vostro ORM come esercizio per capire la meccanica di strumenti più potenti quali Doctrine (o Hibernate on the Java side), cosa che vi sarà molto utile nei contesti in cui magari non potrete metter mano direttamente sul db perché appannaggio di esperti e/o protetto da dinosauri.
La visualizzazione dell'archivio, funzionalità analoga a quella dello snippet d'apertura, è semplicemente:
$bookRepository = new BookRepository();
foreach($bookRepository -> findAll() as $book)
{
sprintf(
'%d. %s - %s',
$book -> year,
$book -> author -> name,
$book -> title
);
}
No array associativi, no sql. Se un giorno doveste scoprire che le query del vostro data access layer sono inefficienti, vi limiterete a pagare dei folletti per aggiustarle, senza compromettere il funzionamento degli strati superiori. Fatemi avere poi il telefono dei folletti, non si sa mai.